If the AI giants like OpenAI, Meta, and Anthropic need human generated training data, that should tell you all you need to know about AI in classrooms.
These information giants demand you label any generated content as AI if you want to continue to use their platform. Freelance data annotation roles from sites like Mercor or Micro1 have taken over LinkedIn. And the reason is AI is not 100% accurate.
How Your AI Works
For some background, let’s talk about how AI actually works. We use a lot of language in AI that is really just intended as gatekeeping. “Prompt Engineering” means asking GPT to do it for you, and does not even involve having the capacity to review the output at the necessary level of expertise. Multishot prompting means giving the LLM a couple examples. You get it.
So the way that AI works, in the most basic terms, is that it is taking the average of all the things inside it. Suppose you ask GPT to generate a picture of a cow and the training data includes 10,000 pictures of cows with black and white spots standing in flat fields, 5,000 brown cows with white bellies with mountains in the background, and 1,000 black cows on yellow clay. the AI will calculate the average of those photos and you will get a black and white spotted cow in a field.
Now if you apply that to using AI generated materials to train AI, you come out with a mess. When generating content with higher level reasoning tasks, there is more variability in the data. Each textbook uses different examples to teach the same learning objectives. The more in-depth a subject goes, the fewer resources are available for copy. Many scientific manuscripts test slightly different aspects of the same construct, but relatively few test the same construct in the same way. There is not much of an average to be found., so it is safe to assume there will be a significant number of hallucinations resulting in the lack of similar data.
This variability means that when you generate a text with AI, some error will appear. It is inevitable. Some tiny hallucinations here and there, or maybe a big one where there is simply not information on that subject. So if you use those generated materials, and all their errors, to train your model, it takes the hallucinations now as facts. As many people lie about their AI usage, a significant proportion of scientific texts are generated with AI. If we use those generated texts that contain hallucinations as the training data, the new model will view those hallucinations as the new facts. If they are big hallucinations because there is no information on the subject, that glaring hole actually becomes the average. And this is where you get model collapse.
Compounding Issues in Education
Most EdTech companies hire software and marketing, but don’t bother to staff much Ed to go with their Tech. The divide has actually grown pretty wide between the two groups. Learning scientists remain in academia while software developers build fast-math and vocabulary apps that function off addiction-based engagement metrics (login, time in app, clicks, pay-to-play) and not education-based engagement metrics (challenge, interest, skill, grit). This means AI-based EdTech companies are often giving no-human-in-the-loop content directly to students who are learning the materials for the first time. Sometimes, if there is a human review process, it is some education professional who is now reviewing samples and forced to play the roles of learning scientist, curriculum designer, assessment developer, subject matter expert in 10 or more subjects across multiple grade levels, textbook author, classroom strategist, classroom psychologist, and more. All while listening to “we ship fast!”
And the worst part of this is the confidence with which LLMs are incorrect. The AI is so close to doing a good job on many topics that facts must be checked line by line, learning progressions built, adequate scaffolding ensured. SMEs and educators have worked together for years doing that with textbooks. multiple editors and reviewers. That does not happen on AI software team deadlines of “ship 10 courses tomorrow with GPT.”
When generating math content, do you really expect a tool that can’t count the r’s in strawberry to teach well the number of significant figures in the final answer? You shouldn’t.
So What if There are a Few Errors?
Okay, so you have correctly noted that humans make mistakes too. There are sometimes errors in textbooks. Sometimes teachers are wrong. So, why is this different?
The difference is trust and scale.
We know humans are fallible so we have a review and editing process for textbooks. We are not doing that with AI. Often, we just have the same LLM or a different one tell us if the first LLM did a good job. If we give children the same respect as the AI giants demand for their LLMs we need to examine the downstream implications of hallucinations in their training data. If children are being given bad training data, do they not suffer the same risk of model collapse?
Students tend to trust their parents and teachers, guides and mentors. If you put a book in front of them and tell them, “this is true you must learn it”, they do so. They do not question the source, the intent behind the manuscript, they learn it as truth. They take that truth into the world, into their own writing, their future work. When we teach them at 80% accuracy, what happens?
So let’s say the LLM has a little hallucination and writes a wrong sentence in the learning material, but then writes the test questions about the material correctly later. A student learns the material well, but then gets the question incorrect on the test later. Worse is if the LLM suffers a larger misconception or is instructed to apply misdirection. In this case the LLM writes the learning materials and the test to reflect a falsehood. The student takes the test, and is marked correct when they answer with the falsehood.
Now we have an artificial feedback loop.
The student may pass the test written by one LLM, but fail materials written by another model. They might perform well with 100% correct on all of the content written by the LLM model, then fail the state or nationally standardized tests.
But my student is really engaged with the content when everything is personalized in the moment, generation is great! Ok. But if each student is taking a different, personally generated test, are those tests measuring the same thing? No, not really. Imagine the agent has assessed that Student A needs materials simplified to better understand them and generates a simplified test. Student B is readigng at a much higher level and the same agent gives them more difficult learning materials and assessments. The result is Student B knows significant more about the topic than Student A, but gets a lower grade in the course because their difficulty was higher. I don’t foresee a single parent being okay with this. Student A is not receiving and equal education and Student B is not being fairly assessed.
You can’t compare two students tests just because they have the same number of questions. There is an entire field of science dedicated to making sure tests measure what they should and can be compared across students and years. But mostly psychometricians don’t make a big fuss. We sit in the background playing with STATA or SPSS and trying to avoid the spotlight.
Comparing at Different Difficulties
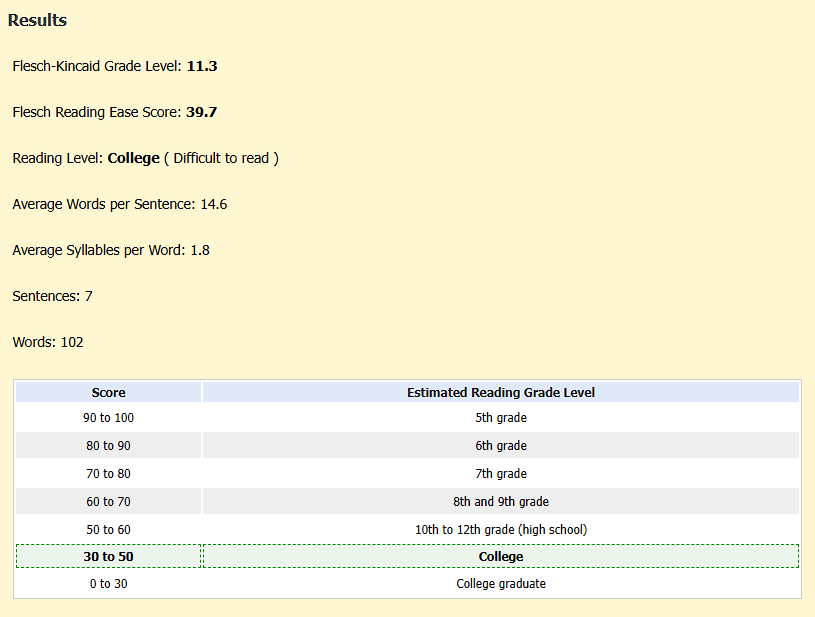
The LLM uses a mathematical formula to calculate the difficulty of a text (see Flesch-Kincaid Readability Tests for an example). While there are a lot of tests most gauge complexity based on sentence or word length. That type of formula is not capable of differentiating between meaning and nonsense (see Begeny & Greene, 2013 for an example). The average reading materials from social media and news sites are written around a middle school level of comprehension. That is what the LLM outputs comfortably (see Readability Score in AI Content: Why It Matters? by Ramesha Kamran if you are interested in more details.).
Using the Flesch-Kincaid Calculator from Good Calculators, the above paragraph scores the following.
I have performed a little experiment if you would like to see what happens for yourself.
When Will AI Be Safe for Students
The probability of ever achieving 100% accuracy on such a task is approximately 0%. While LLMs are showing better performance on lower grade levels, the depth of knowledge is considerably lacking and the accuracy becomes abysmal at higher levels of difficulty.
Consider that “correct” is no longer binary with deeper reasoning. Two researchers will compete for dominance of studying the same concept by defining it in such subtly different ways the two terms are intertwined. Depending on who you are citing in your own work, you need to know these differences. But neither is incorrect, it is simply the definitional foundation.
In my own research doing data annotations to train a supervised ML model, I can tell you it is difficult to get humans to agree on how to classify data. Meetings upon meetings are required for training human raters. You need to train them to a kappa (percent agreement corrected for chance) of about 0.80 in the hopes of getting a kappa > 0.70 which is where you can talk about your findings . For ML, a human-to-machine agreement of >0.81 is considered near perfect and is the standard. Mercor and Micro1 dont seem to have group training meetings.
Giving LLMs too many instructions or expecting too much output has a much higher risk of skipped instructions or hallucinations. So once you add instructions for depth of knowledge, reasoning, formatting, grade level associations, and a knowledge progression based on previous lessons, at least 2 of these are being skipped entirely.
And finally, too many researchers are failing to review their GenAI output before putting a manuscript into print and lying about it being fully written by human hands. Publishers are facing significant costs due to hallucinations that force redactions, and the chain effect that has across citations.
I don’t believe we are ready for no-human-in-the-loop writing yet, and I don’t foresee this happening any time in the near future. Maybe one day. AI is a truly powerful tool for doing very average tasks, but it must be met with clarity of vision and expertise when implementing this technology into such impressionable and intimate spaces as teaching our children for the first time.
In Conclusion.
Why don’t students have the same right to demand human annotated training data?
They do, and as their parents you must uphold this right while you still can. If poor training data can cause a model to collapse, what is it doing to your children?
We must demand human experts, reviewers, subject matter experts, psychometricians, learning scientists, and education professionals are developing materials together. Not one person picking up every role. Not a software technician substituting an LLM for all of those experts.