
I am accused of being against AI. But I am not. I actually LOVE working with AI. The reason I am accused of being opposeed is that as a quantitative analyst, I believe in reliable performance metrics and expert review. I have reviewed the accuracy of multiple LLMs across something like 1000 topics in 11 subjects in science, history, and social science. I can tell you with absolute confidence that this is an emerging science. And it should be studied as such. It is an incredible aid to speed up processes, a thinking tool, a partner. You should think of AI adoption like a new intern, still in school. Sometimes it feels like the owner’s latest nepotism hire and other times like colleague able to write a report at 100x the speed. But always, the output needs a review before being passed to children in the classroom.
So let’s talk about AI adoption, not as a binary state of technophobe vs full automation, but as a nuanced and intelligent discussion with relevant information on both sides. I am going to develop this conversation from the framework of the primary skills taught in high school history and social science courses. We are going start the conversation with a focus on AP Historical Thinking Skill 2: Source Analysis.
Skill 2: Sourcing and Situation
Analyze sourcing and situation of primary and secondary sources.
- 2.A Identify the source’s point of view, purpose, historical situation, and/or audience.
- 2.B Explain the point of view, purpose, historical situation, and/or audience of a source
- 2.C Explain the significance of a source’s point of view, purpose, historical situation, and/or audience, including how thse might limit the use(s) of a source.
Skill 2: Sourcing and Situation
2.A Identify the source’s point of view, purpose, historical situation, and/or audience.
LLMs have become a popular source of information for many people around the world. While they are as providers of information, their purpose is to protect investors’ interests meaning that the point of view being shared is that of a corporation protecting its fiduciary responsibilities. Who then is the audience? The audience is you the consumer, the potential buyer of goods and swayed voter.
2.B Explain the point of view, purpose, historical situation, and/or audience of a source
Historical Situation
Google Gemini will be our starting point as it has arguably positioned itself as the number one source of information and first point of contact with a web search. Google is unarguably the world’s most popular web browser. But it is important to remember Google is a for-profit organization selling your data to marketers to give you targeted ads. The first thing you typically see when looking for information is either a list of products or the Gemini summary of your search results.
Responsibility to the Truth or the Shareholder?
Google does not claim Gemini search integration results to be a factually accurate source of news or information. Quite the contrary even.
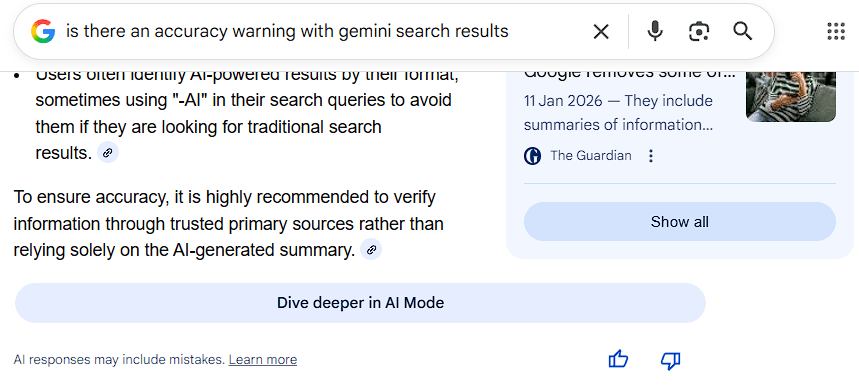
With the use at your own risk type disclaimers and extremely broad EULAs that remove any liability for misinformation, what is the benefit to shareholders in spending more money for expert review? There is none. In fact, a for-profit corporation may be sued by shareholders for wasteful spending that does not fulfill the fiduciary duties to increase shareholder profits. This is a much greater risk than one user attempting to sue after failing to read the disclaimer.
Purpose: Protect The interests of the Shareholders
One must then identify who are the shareholders and investors in the LLMs and AI that we are using?
According to multiple sources, Google’s primary source of revenue is targeted ads. Google allows clients to purchase specific search terms that will trigger ads for for their company, specifically displaying them to a targeted audience. Investopedia cites Alphabet’s top shareholder as Vanguard Group, BlackRock, FMR, and JP Morgan Chase, Larry Page, Sergey Brin, and L.John Doerr.
OpenAI reports a long list of founders, donors, and investors incluciding Sam Altman, Elon Musk, Reid Hoffman, Jessica Livingston, Peter Thiel, and Amazon Web Services.
TSG Invest cites key investors in Anthropic as Amazon, Google, Microsoft, Nvidia, ICONIQ, Lightspeed Venture Partners, Fidelity, Spark Capital, Salesforce Ventures, Menlo Ventures, Bessemer Venture Partners, BlackRock, BlackStone, Coatue, D1 Captial, General Atlantic, General Catalyst, GIC, Goldman Sachs Alternatives, Insight Partners, Jane Street, Qatar Investment Authority, TPG, and T. Rowe Price. As well as a partnership with Palantir to provide Claude services to U.S. intelligence and defense agencies.
This is a broad list of for-profit stakeholders investing in the information being delivered to end consumer which is both good and bad. But we will get to that shortly.
Point of View: What Is Being Shared
These major players in AI development are cross investing. So the purpose is not only to protect themselves but to also protect their fellow AI developers. Laws that favor few consumer protections and vast energy consumption will benefit will benefit the AI Company, and consequently their investors. I want to be very clear that this is not a left or right debate. The technocracy is spending their dollars on both sides of the fence to sway lawmaker and public opinion. So this is merely a discussion of who is training the algorithm and whether they have a stake in the output.
These investors and partners are involved in large political PAC donations that influence your government. I went to OpenSecrets.org, to see how much some of these groups spent on lobbying and political donations in 2024: Alphabet Inc spent $14,790,000 on lobbying ; Palantir Technologies spent $5,770,000; Microsoft Inc spent $10,353,764; BlackRock Inc spent $2,840,000; Amazon.com spent $19,140,000; and Peter Thiel personally dumping millions into various PACs across multiple states.
Remembering these are all for-profit corporations or investment groups who make those investments on behalf of their shareholders: it would be counter to their own interests or those of their shareholders to make investments that do not benefit clients or could cause harm to their clients’ shares. The point of view being shared to the end consumer must then be of benefit to the large body of stakeholders, not harming one investor by favoring another. The large number of shareholders then is of benefit to the consumer because it prevents the output from becoming a direct advertisement for any one source of funding.
Equally true, is that these projects would be a poor investment if they did not provide factually correct output at least most of the time. If LLMs only output advertisements for the investors, there would be no product because no one would want to consume it. So there is a motivation to accurately summarize news stories, and output factual replies.
So we can assume here the information will be mostly factually correct but with a strong risk bias. This is a product meant for consumption so it must appeal to the consumer, but the legal responsibility is to the investor. So output must be approached critically and should be assumed context dependent. It is very possible, if not probable that any information that could be counter to their political goals or damaging to other clients have been removed from training data.
Audience: The Consumer
So what is being given to the consumer?
What is the product being consumed?
It is a mix of a factually accurate and useful search and generation tool, that contains the same opinions of its host and is limited to the data they are willing to share. The consumer is the person who will buy their product, pay for their subscription, watch their ads, and hopefully vote in the best interest of the company.
2.C Explain the significance of a source’s point of view, purpose, historical situation, and/or audience, including how thse might limit the use(s) of a source.
So how does the purpose of output impact the implementation of GenAI? It means that it must be approached critically. It should be used as a writing tool, but not a tool that replaces human review or thought.
We want students to learn facts. We want our students to have the knowledge they need to be safe and grow. To approach their environment with caution and care. And to understand facts, and apply that information in new situations.
Is there a motivation to provide accurate and unbiased content? Yes, because this creates a product that people will consume. If the tool is never useful it cannot be adopted for content generation. Is the output filled with errors and hallucinations? Yes. There is even a disclaimer putting the responsibility of verification of facts onto the end consumer.
So yes, absolutely we can generate classroom content with AI! Chat GPT can write distractor options much faster than I can manually. It can assemble paragraphs, create summaries, and check student responses for accuracy. AI can write lesson plans. What is limited here is the ability to put it in front of students without review.
When implementing GenAI in learning spaces we must approach the output carefully with expert review. If AI models cannot be trainined on AI generated content because the errors become part of the training data, we cannot train our students out the same error ridden output. Our students must be taught with factually accurate materials that have been verified. If we teach them errors as correct, they will carry those errors in learning over to their own students.

LLMs already show low performance on many generative tasks at the high school or university level in science and math. And we must be exceptionally careful when a factually correct output might conflict with the interests of the major corporations that want to sway your opinions! Is there a motivation to show biased output? Yes, if it benefits the shareholders and reflects the views of those holding the data. This could be information intended to sway public opinion on Data Center locations, not discussing concerns over water safety, or slightly modifying responses to questions about investors to respond more positively than truthfully. Consumers are also voters and may be influenced by what the algorithm shows them in a given search. Is there a motivation to support misinformation? Yes, if it benefits the shareholders. There is already an error allowance and use at your own risk disclaimer. There is room to intoduce intentional bias without risk. And again, consumers are still voters.
Coming soon…
In my next post, I am going to show a real world example of recently generated output from Gemini that supports the need for a source analysis related to what we are discussing here.
